There are more and more good visualization tools available for clustering your DNA matches with the intent of discovering a new ancestor. Recently I’ve been using a clustering tool created by Evert-Jan Blom at Genetic Affairs (more on that tool in an upcoming post).
The DNA Color Clustering method used by Dana Leeds clustering methodology is straightforward, and especially effective for those persons who have many 2nd and 3rd cousin matches on Ancestry — which I don’t. (Although it actually works quite well for more distant cousins, in my opinion, especially if you’ve been working on clustering your matches for several years!) You can find out more about Dana’s method here.
Despite these cool clustering methods — and others — in the end, I keep returning to my trusty Excel spreadsheet and my list of “ICW” (In Common With) matches from Ancestry.com which I download using the DNAGedCom client tool (available here via a yearly subscription).
I’m sharing my way of clustering my matches — or, more specifically, my mother’s matches and my father’s matches — because the “best” method is the one that makes the most sense to you, or seems the most “intuitive”.

Some of Mom’s shared matches with “Cousin B”, on Ancestry
Let’s say I’m working with my mother’s DNA matches from Ancestry.com. Using the DNAGedcom Client tool, I will download a list of all her matches, and then download a list of all her “ICW” matches into CSV format.
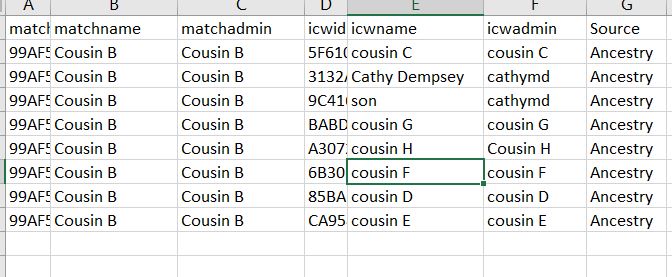
This is a sample of the default ICW file, before I combine it with the default Match file.

This is an abbreviated sample of the default match file. The columns of interest are “Range” and “SharedCM”.
Once I have the two files, I use the VLOOKUP tool in Excel to associate (Cousin) Range and SharedCM to the primary match, and then to the In Common With matches. The result is a combined file like that below. The combined columns are highlighted in green.
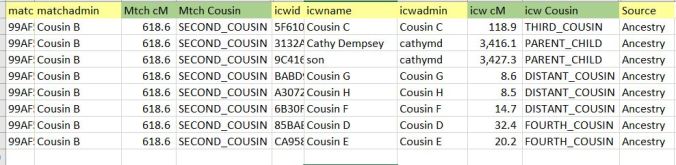
The “Mtch cM” and “Mtch Cousin” columns associate to Cousin B; the “icw cM” and “icw Cousin” associate to the ICW match: me, my brother, and cousins C, D, E, F, G, and H. Shared cM (centiMorgans) = shared DNA; see my previous post here for more on centiMorgans.
For purposes of clustering, though, all we really care about is that in general, the more DNA you share, the closer you are related — at least in the case of 2nd cousins or closer. You can see that to some extent with Ancestry’s predicted ranges in the green highlighted columns.
The In-Common-With (ICW) list is basically a subset of your matches list. My mom’s paternal first cousin — let’s call her “B” — has also tested at Ancestry. So, Mom’s ICW list for “B” would include me, my brother, and six other cousins: C, D, E, F, G, H. (Mom’s father was a first generation American, and “B”‘s father was born in Italy — not a lot of our Italian side, many still residing in Italy, have tested their DNA on Ancestry. Hence, we don’t have a lot of matches.) The critical point is that C, D, E, F, and G as well as my brother and I would show up on Mom’s match list AND on B’s match list — we are the “in common” matches.
So, if Mom and cousin “B” are first cousins, their Most Recent Common Ancestor(s) (MRCA) would be their shared set of (Italian) grandparents: Guiseppe Diamantini and Maria Bolognesi. Obviously that same couple would be the great-grandparents of my brother and me. But my brother and I are not the interesting cousins in the ICW cluster. Cousins C, D, E, F, G and H are the key here.

Let’s look at the example above. I “cluster” my mom’s DNA matches by adding two columns (shown here highlighted in red). Because I know my mom and Cousin B share the same set of grandparents, I put the MRCA couple’s name in the “Mtch MRCA” column for each row where there is an In Common With cousin. (Note that, despite Ancestry’s prediction that my mom and Cousin B are 2nd cousins, they are in fact 1st cousins.)
The amounts of DNA shared, shown in the “Match cM” column and the “icw cM” column are the amounts Mom shares with these cousins. We cannot determine from the information shown here how much, if any, “B” shares with “F”, or “C” shares with “D”. We only know C, D, E, F, G, H not only share DNA with Mom, but MUST also share some amount with Cousin B because Ancestry has given us that information.
I then look at each of the ICW cousins: that is, my brother and I, plus cousins C through H. I note that my brother and I are children, which means our DNA amounts won’t have any new information to determine cousin clustering — because whatever we share, we inherited from Mom. (You can always exclude known children of a DNA match when you’re working with clustering, because they will always be a subset of their parents — if you have your parents or grandparents tested.)
Cousins C and D are two people whose place in my mother’s family tree I already know — therefore I include their MRCA information (Fortunato Camillucci and Maddelena Serafini). They are my mother’s cousins on her Diamantini line. Since the Diamantini line is my mother’s paternal line, I shade it blue for male.
Cousins E, F, G and H are unknown to me. In this case, none of them have trees on Ancestry which might give me more detailed information as to how they relate to my mother. The amount of DNA shared is fairly small, so it is possible the Most Recent Common Ancestor (MRCA) with Mom is quite a few generations back. So I note them as “Diamantini or Bolognesi” (as I don’t yet know whether they share on the Diamantini line or the Bolognesi line) and also shade the cell in blue. I leave those notes unbolded, since I’m not certain of how the cousin actually fits into our tree.
I then do the same thing with each of the other cousins listed here. Below is a screen shot of the In-Common-With listing for Mom and Cousin C. Note that there is some overlap with the In-Common-With listing for Mom and Cousin B, but there is one person who shares DNA with Mom and Cousin C, but who does not share with Cousin B. I labeled that person Cousin J (highlighted in bright yellow.)
 Because the Most Recent Common Ancestor between Mom and Cousin C is the Camillucci & Serafini couple, I then use those names to populate the cell in the icw MRCA column, as shown below.
Because the Most Recent Common Ancestor between Mom and Cousin C is the Camillucci & Serafini couple, I then use those names to populate the cell in the icw MRCA column, as shown below.

Mom doesn’t have that many matches on Ancestry.com to her paternal side, in part because her father was a 1st generation American. A better example of the clustering is shown below, with one of her 4th cousins. The shared Most Recent Common Ancestor between Mom and cousin “K D” is Jacob Copple and Margaret Blalock.
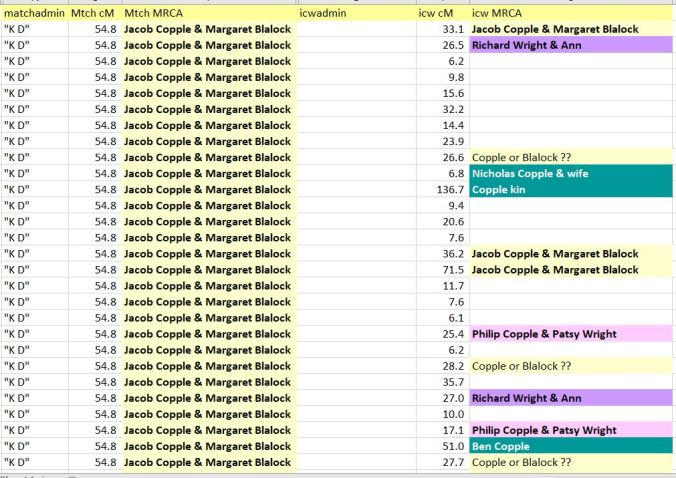
I have hidden the names of the In-Common-With cousins, but you can see the amount of DNA they share with my mother. What this screenprint shows is how the different In-Common-With cousins have different Most Recent Common Ancestors with Mom. But all of them are related in some way to either Jacob Copple or Margaret Blalock. Philip Copple and Patsy Wright, for instance, are the presumed parents of Jacob Copple. Patsy Wright’s presumed grandparents are Richard Wright & Ann. Ben Copple is the son of Jacob Copple & Margaret Blalock, while Nicholas Copple & wife are the likely paternal grandparents of Jacob’s father Philip.
A different cousin of Mom’s who also descends from Jacob Copple & Margaret Blalock possibly inherited some of Margaret (Blalock) Copple’s DNA. You can see that in the ICW MRCA column below, where some of the In-Common-With cousins (names are whited-out) appear to have Blalock / Blaylock lineage. One of the cousins who shares DNA with both Mom and “M M” is fairly closely related to Mom; you can tell that by the amount of DNA shared (140.4 cM) and the MRCA = Sam Englehart and Libby Copple. Libby Copple is the granddaughter of Jacob Copple & Margaret Blalock.
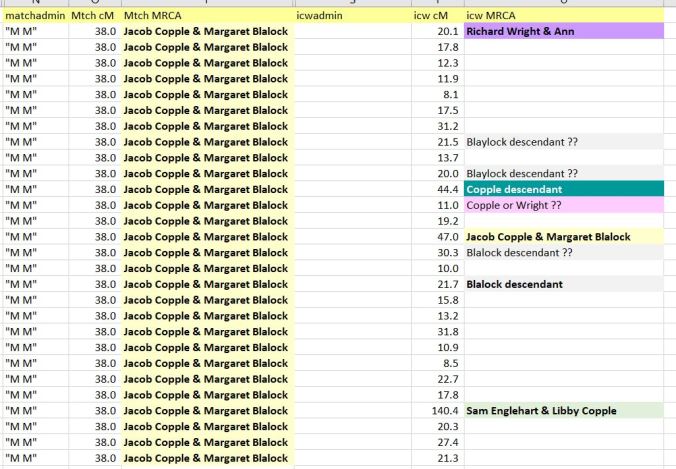
All in all, this is just one more method of using color coding and Most Recent Common Ancestor information to figure out how your unknown matches may be related to you. It’s not an absolute — it’s just a hint. But it gives you something to work with.
