I saw from following DNASleuth’s blog that Ancestry has a new ethnicity feature, wherein your received ethnicity is assigned to either Parent 1 or Parent 2. So, naturally, I had to check it out. Ethnicity estimates were also revised!
My dad formerly (as of last week) was listed at 100% Irish. He is no longer. Now he’s 90% Irish, with the remaining 10% being Scottish and Welsh. And, honestly, in the past, AncestryDNA has shown him with Scottish, Welsh, and even English ethnicities. It all depends on the calculation at the time, I guess.
All that said, I believe this estimate is quite in line with the paper genealogy, and the birthplaces of my great-grandparents. I have 4 Irish/Celtic great-grands, 2 Italian great-grands, 1 great-grandparent whose parents were born in and immigrated from southern Denmark, and one great-grandparent whose line in the U.S. extends back to early 1700s and is largely of German and English descent.
I have recently created a Copple surname group on Facebook for persons interested in DNA, genealogy and researching their Copple kin. This private group is all about connecting with folks who have a Copple line in their family tree, and trying to tie DNA test results to that Copple branch. Variant spellings include Copple / Cople/ Cobble/ Cauble/ Capple / Gobble.
If your DNA/genealogy interests or your family tree branch includes Copple, please consider joining! You can check it out here.
Last week in the “Genetic Genealogy Tips & Techniques” group on Facebook, Blaine Bettinger posted a study of his own 4th-cousins-and-closer matches on Ancestry.com which can be viewed here. I decided to do the same. These are my results:
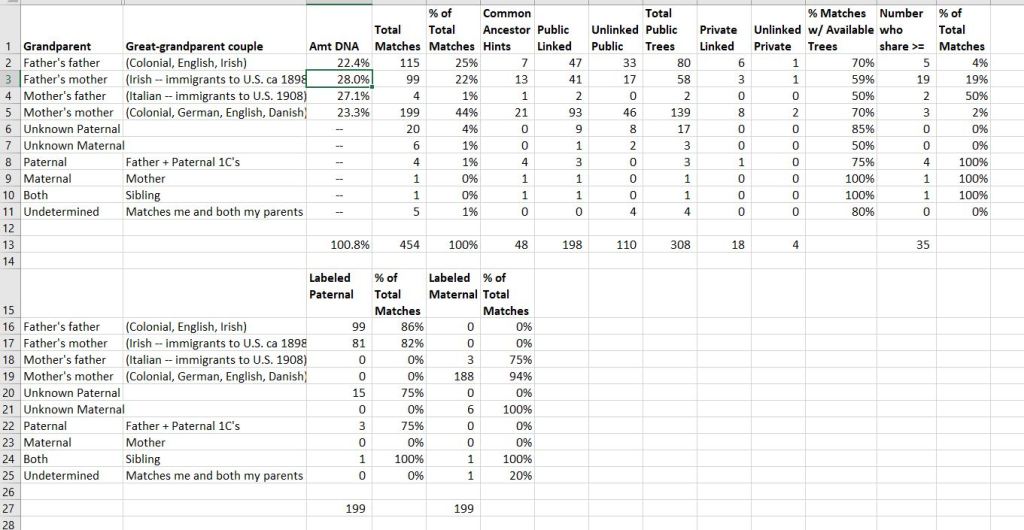
Cathy’s 4th cousin (and closer) matches on Ancestry.com
Matches which are included here are matches who, in general, share at least 20 cM of DNA with me (although I have some matches at the 20 cM level who are labeled as “distant” cousins).
The “Amt DNA” information does NOT come from Ancestry; it comes from having done a process called “chromosome mapping” or “visual phasing” and it required the DNA results from both my parents, as well as from my sibs, compared against that of my 1st and 2nd cousins who have tested. On my dad’s side, the amount shared skews towards my grandmother, in part because one of my X chromosomes comes from her and her alone.
The number of matches sharing >= 50 cM with me also skews towards my paternal grandmother because 2 of my dad’s 3 maternal 1st cousins have tested at Ancestry, as well as some of their children and grandchildren. All are no more distant than 2C1R to me. (Note: in that figure I do not include my dad, my sibling, or my paternal 1st cousins — since they share both paternal grandparents with me.)
However, in total numbers of matches, my two grandparents with “colonial” ancestry (and by that I mean roots in the U.S. at least as early as 1790 — but not necessarily as far back as, say, 1650), are the ones with the most matches. That seems to correlate with what I’ve heard from others who have tested at Ancestry. My paternal grandfather has one line — his maternal grandfather — that is “colonial”. My maternal grandmother has 2 lines — both of her maternal grandparents are “colonial”.
I compared the paternal and maternal labeling, but it doesn’t tell me much, in my opinion. Ancestry only labels the DNA match as paternal or maternal if the match is >= 20 cM for both parent and child. Where there are differences in the totals, it is due to the match being >= 20 cM for me, but not for my parent. That’s an artifact of the computer algorithms.
Finally, tree availability in and of itself may not be the be-all end-all for matches. 85% of the matches I identify as paternal unknowns — I cannot discern which grandparent they are kin to — have public trees. The trees have done nothing to help me figure out how that match is related to me! Any suggestions?
As is the case with everyone who has had a DNA test at Ancestry, my small matches are gone. (However, I did go through the match list of my parents and my sibling and 1st cousins, “saving” small matches that were of interest (like “Thru Lines” matches) by marking them with a group identifier or making notes.
For me, the issue was removing old notes for small matches where I had indicated “doesn’t match mom or dad” so those false matches would not be saved!
The blessing of having both your parents alive and willing to test means you can check any of your own matches to validate whether they match one of your parents (if your parents give you collaborator access). I had already determined — via 3rd party tools — that over 25% of my matches were invalid. Meaning they didn’t match one of my parents.
So, all in all, I’m not at all upset at losing matches. Especially if it speeds up server response time.
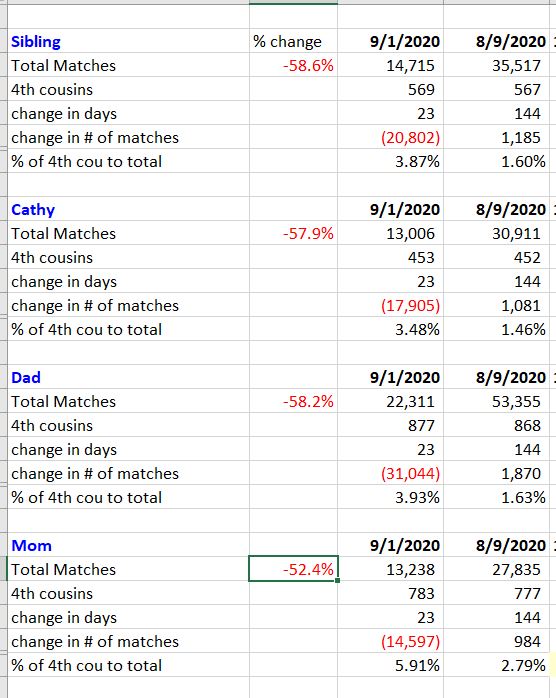
How many matches did my family members and I lose? Over 50% in each case!
The reduction in matches (everyone with < 8 cM of DNA shared) isn’t the only change. Ancestry also updated the number of shared segments with your matches. Mom and Dad still show more than the 22 autosomal segments they share in actuality, but it’s a lot closer. You can see that all he segment numbers go down for my matches with my closest kin.
My segments with my father were always fewer than with my mother. One reason is that there are fewer recombinations passed down from males, as I understand it. Another reason may be that my dad and I tested back in 2012, and therefore tested under a different version than my mother, who tested years later.
Here’s a list of my mom’s top matches, noting old number of segments compared to new number of segments. Segment number only changed when appropriate, so some of these 50 cM matches show no change.
The last change at Ancestry DNA was the addition of longest segment information. From what I’m hearing, this feature will be most useful to those who have significant endogamy in their ancestry (Acadian French, Ashkenazi Jewish, etc.) However, it can be useful if your match has tested elsewhere, and you have the chromosome segment information.
For the match below who has tested elsewhere, I already know that my mother’s (and mine, for that matter) primary segment match is on chr 9, and is hugely long (60 – 90 cM) per other vendors. So, seeing the below information validates that Ancestry shows the match on chromosome 9 as well, despite the fact they don’t tell you where you match.
The longest segment is calculated before Ancestry’s algorithms massage the data by removing “pile-up” regions (shared by many people) which are not considered genealogically relevant.
Hurray! It’s finally arrived! My dad and I took Ancestry DNA tests 8 years ago in the fall of 2012, and it’s always bugged me that Ancestry said we shared 55 segments of DNA when we know the true biological number is 22 shared autosomes and 1 shared X chromosome, the full length of the chromosome. So we should have seen 22 all these years (because X isn’t counted).
Well, it still isn’t 22, but it’s a darn sight closer!
The shared segment count with Mom is still pretty far off, but at least it’s not 77 any more. I suspect the count is due to Ancestry’s algorithms and/or the chip that was used for her test which was done in fall 2018. Mom also tested at FTDNA (a native kit, not a transfer) and that FTDNA test was the one uploaded to MyHeritage; they’re largely in agreement as one would expect.
The 1st cousin relationship looks fairly consistent the board.
I also noticed that the segment count for my Mom’s Ancestry matches mostly remained the same past 2nd cousin, down to matches of 30 cM, while my matches and my Dad’s matches down to 30 cM showed more adjustment in the segment numbers. Just a fluke? Or something to do with the testing chip used?
Did you see changes? There are polls being done at the Genetic Genealogy Tips and Techniques Facebook group here.
Margaret [J?] (Blalock) Copple (b. ca 1810 in Kentucky – d. 1892 in Newton County, Missouri) was one of my 4th-great grandmothers, and is a “dead end” ancestor. I do not know her parents, but I do have some leads. I really need to make finding her parents one of my future research goals – and the “future” is arriving now, in 2020.
What do I know about her right now? And what leads do I have?
The Basics, Documented (in my Ancestry tree)
Born in Kentucky (per her responses on census records) – where exactly I don’t know.
Was in Washington County, Indiana by December 1827, when she married Jacob Copple on 6 December
Not (yet) found in the 1830 census. Presumably in Indiana.
Was in Vigo County, Indiana at the 1840 census
Was in Newton County, Missouri at the 1850 census
Was in Newton County, Missouri at the 1860 census
Not found in 1870 census for either Newton or Jasper counties
In Newton County, Missouri in 1871, as administrator of her late husband’s estate
Reportedly died in 1892 in Newton (or Jasper) County, Missouri
Is buried in Jasper County, Missouri
Other Clues
Two men, a Jeremiah Blalock and a Thomas Blalock, both old enough to be Margaret’s father, were in Washington County, Indiana in 1830. They lived next to each other.
A Jeremiah Blalock married a Louisa Dosier in 1835 in Vigo County, Indiana — the same county Margaret lived in at the 1840 census.
A “Jer [for Jeremiah?] Blalock” lived in Lancaster, Garrard County, Kentucky in 1810. A female < 9 years old resided in the household. Could this be Margaret? A “Jer Blalock” lived in Rockcastle County, Kentucky in 1820. In that household was a female 0-9 years, and a female 10-15. Could the 10-15 year old female be Margaret?
A David M Blalock married Lucy Carey in Washington County, Indiana in 1831. Lucy Carey and David have at least 4 children before Lucy dies ca. 1840.
Lucy Carey was the daughter of John Carey and Polly Hungate.
David M Blalock married Mary “Polly” Norton in 1841. They had a daughter Margaret Jane. All are on the 1850 census. David was of an age to be a possible brother of Margaret (Blalock) Copple.
David apparently died ca. 1853 because Polly (Norton) (Blalock) marries again ca. 1854.
Andrew J Blalock, son of David and Lucy and possible nephew of Margaret (Blalock) Copple, lived in a Hungate household in 1860 in Washington County, Indiana.
The youngest son of David M Blalock, his namesake, born ca. 1850, was married in 1879 in Jasper County, Missouri. What brought him south to Missouri? Could it have been a family connection to a paternal aunt and cousins?
DNA Clues
Through DNA clustering tools, I’ve been able to determine that Mom (and I) have segments on chr 9 and chr 13 which are almost certainly inherited from Margaret (Blalock) Copple rather than her husband Jacob. There is also a third Blalock segment which shows up in clustering tools
Numerous DNA matches of Mom have Blalock/Blaylock in their trees (where trees exist), but there is no consistency in the names and locations, as there was for my Copple line.
Some DNA matches of Mom have Hungates in their trees, and some of those have Hungates living in Washington County, Indiana at the same time Margaret’s family lived there.
A fairly large number of Mom’s DNA matches which cluster in the “Blalock” cluster have a shared common ancestral couple: Thomas Hemphill and Mary Mackie. Other matches share a common ancestral couple who are Thomas Hemphill’s parents. If the ages in the trees are to be believed, these couples would be of an age to be Margaret’s grandparents or great-grandparents. The DNA link may not be with the Hemphill line at all, but without further investigation on my part, I cannot rule it out.
Next Steps Research all of the Blalocks living in Washington County as of 1830, including census, marriage, land deeds, court records, etc., in particular both Jeremiah and Thomas Blalock. Continue to attempt to sub-cluster Mom’s matches by Blalock common ancestor, if there is one, focusing particularly on Blalock connections in southern Indiana, and Kentucky.
The other day I posted about how some of my Ancestry DNA matches looked on in the Shared Clustering Tool. Today I’m comparing that same cousin — my 4th cousin 1 removed and my mom’s 4th cousin — against my Mom’s Ancestry DNA matches both in the Shared Clustering Tool and Node XL.
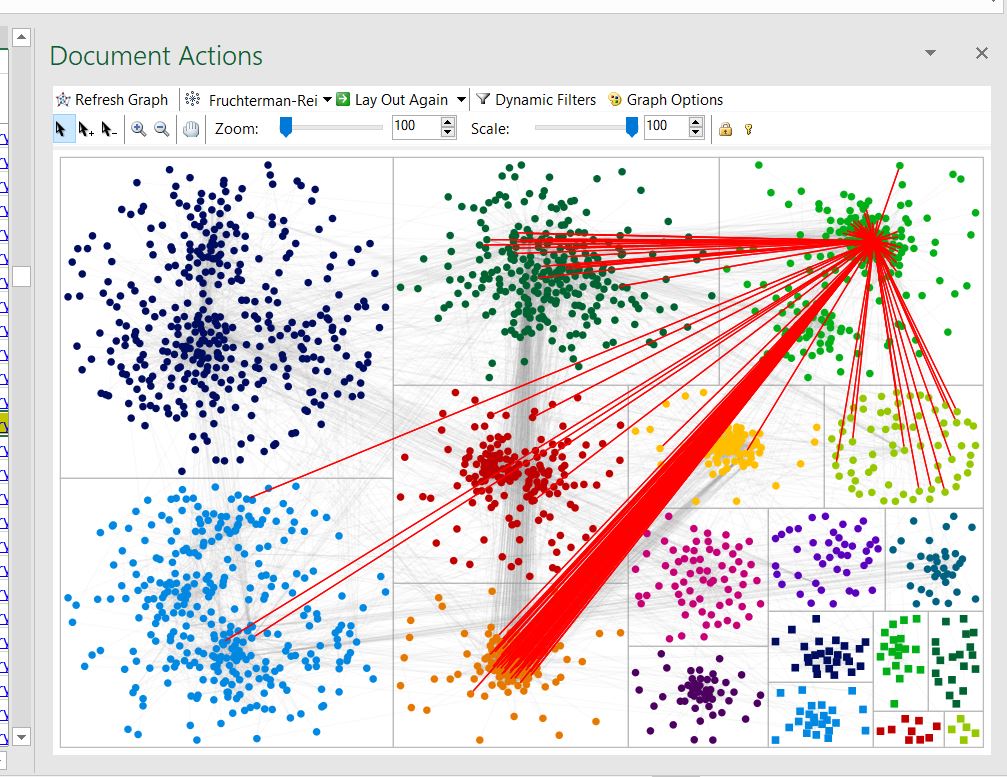
Cousin “Jane” (as I’ll call her) shares a set of 3rd great grandparents with my mom: Jacob Copple and Margaret (Blalock) Copple. She shares 71 cM in 4 segments with my mom, according to Ancestry. I can see 3 of those segments clustered in the Shared Clustering tool. One segment appears to tie to matches with a Blalock/Blaylock in their tree and/or a segment on chromosome 9 (based on those matches who are also on 23andMe, FTDNA, MyHeritage or GedMatch). A second segment matches another possible Blalock segment, likely on chromosome 13. Finally, a third segment cluster is with matches whose MRCA is likely Jacob Copple’s parents (Philip Copple & Patsy Wright) or grandparents.
The orange line vertical and horizontal (in both pictures) represents cousin “Jane”. The three blue arrows above show the three main clusters she shares with Mom and with other matches of Mom’s.
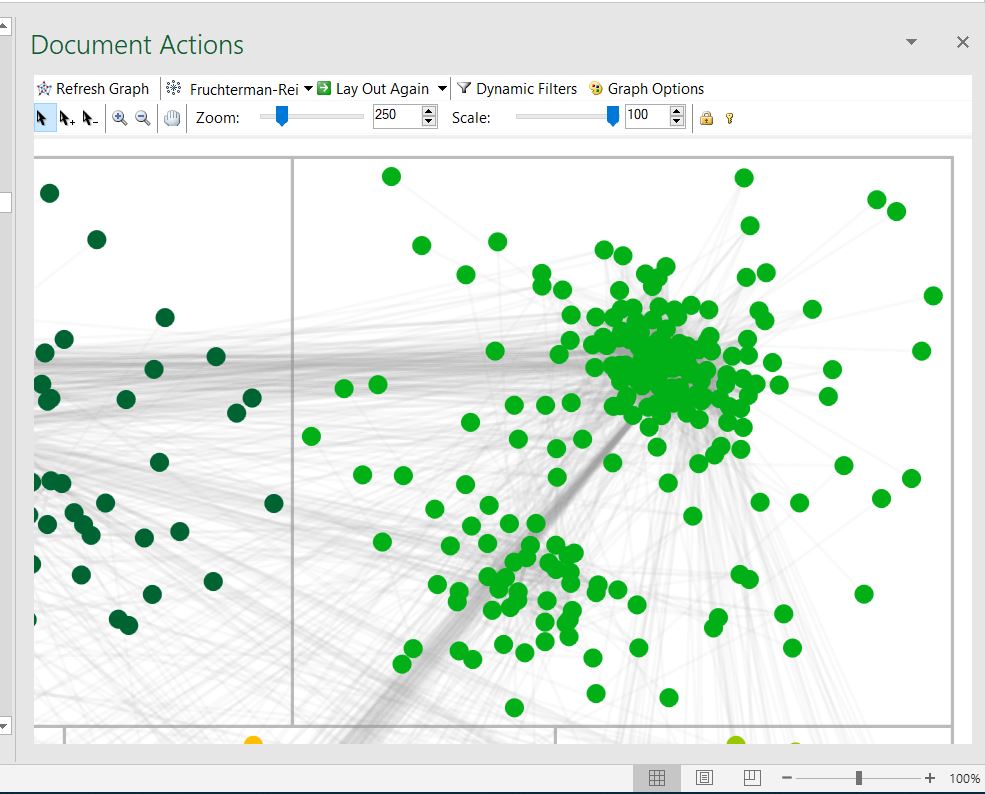
Below is a zoomed-in look at the “chromosome 13” segment cluster.
Below is the likely chromosome 9 cluster. The blue labeling in the rows and columns represent matches who have a Blalock/Blaylock in their own trees. (Of course, the shared DNA may be due to another family line altogether, but the evidence at this point seems to be hinting at Margaret Blalock’s line rather than her husband Jacob’s.)
Can I see three clusters for “Jane” using the Node XL tool? Actually, yes, I can. The Node XL tool is not as intuitive to use as the Shared Clustering tool, and I don’t know the algorithms behind either, but it’s reassuring when different clustering tools give somewhat similar answers!
Cousin “Jane” is highlighted in red. She is based in the green group, and matches the hunter-green group, the chartreuse group, and a whole bunch of my mother’s matches in the gold group. The Node XL clusters are limited to Mom’s matches of at least 15 cM.
I haven’t done enough research with the groups in the Node XL tool, but I was intrigued by “Jane’s” cluster. It looked like there were actually two groups — and sure enough, there are two groups, as you can see below. I’m not sure why the cluster was not split out in a definitive manner, as there is not a lot of crossover between them.
If you’ve used Node XL regularly, do you know why that might happen? Perhaps it’s the algorithm used?
Finally, in addition to more study of Node XL, I need to run a clustering report on the Genetic Affairs tool, which I haven’t used much. It would be interesting to see how “Jane” clusters with my mom’s closest matches using that tool.
One year ago today I started this blog. I had intended to write regularly — at least once a week — and I do, in fact, have 52 posts. (Although I’ve arguably cheated a bit with my “Throwback Thursdays” series look at family photos, and my more recent “Copples in the News” series on Fridays.
With one year under my belt, I thought I’d look at my blog stats. What’s my most popular post? How many people have visited, and from where? Let’s see…
Here’s a graphic of all-time views and all-time individual visitors. I have to see all these numbers are much higher than I expected since I’m primarily focused on my own family history and what I’m learning with DNA.
What countries are they from? I’m guessing WordPress counts spammers, too? (Not sure, but I suspect so.)
Finally, my most viewed post (after the main page) was my review of the BU Genealogy Certificate class. Fully 25% of the visitors to my blog this past year checked that out. The next top 5 posts viewed all related to DNA — specifically clustering matches, Blaine Bettinger’s Shared cM Project (which is ongoing as of this writing), and 23andMe’s ethnicity update.
I haven’t kept up well with the “52 Ancestors in 52 Weeks” series. That’s okay. It’s going to hold limited appeal — unless one of my ancestors is also yours. The top-rated post in that series (which I did not do for a full 52 weeks!) was the very first one, featuring my maternal grandmother who died at the age of 26. Fitting, really, because in many ways, it was the fact that my own mother knew fairly little about her that got me started in genealogy.
So, for the next year, while I’m still going to continue my “Copples in the News” series, and post more of my research, I will certainly post about what I learn by clustering my own matches, as well as those of my dad and my mom. I hope it can help others. We can all learn together!
Thank you for reading, and here’s to another year of learning about our genes and our roots!
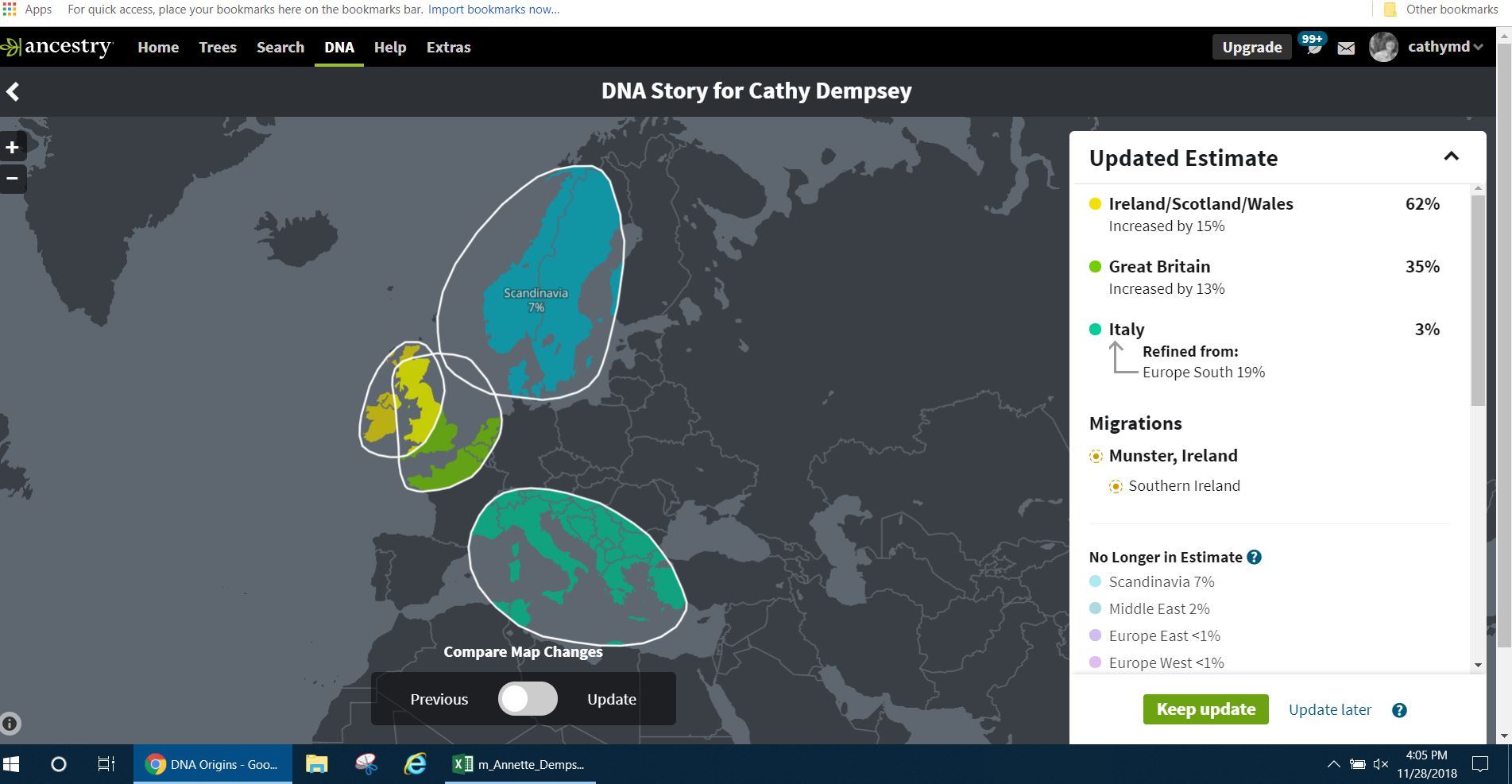
Ancestry is apparently in the process of updating ethnicity percentages yet again. I got an email today from them, and checked it out. The change is not particularly significant for me, but keeps getting farther from the “truth” (i.e., my maternal grandfather was a 1st-generation American, born to 2 Italian immigrants.) One of my male cousins on that side has done the Y-500 test at FTDNA; his haplogroup (which should also have been my grandfather’s) has deep roots in the Italian peninsula.
Here’s what it was as of the last change (September 2018), when my Italian was dropped from 19% to 3%:
That was the big shift. The image below shows what it is now as of today. What IS very much in line with my family history is the southern Ireland genetic communities, such as Co. Clare, Co. Limerick and Co. Kerry. (The Irish ethnicity is all on my paternal side.) The Germanic Europe and Northwestern Europe which appears to include Schleswig-Holstein is also in line with my maternal roots.
It’s just the lack of Italian heritage — which shows up on FamilyTreeDNA, MyHeritage, 23andMe, and GedMatch — is really my only quibble with Ancestry’s results. (And it may be due to Ancestry’s customer population being heavily weighted towards persons of European ancestry who have (relatively) deep roots in North America.)
My mother and my brother apparently have not gotten their updates yet. If you’ve tested at Ancestry, have you seen a recent update to your ethnicity? If so, how did it change?