I posted my dad’s NodeXL clustering results a few weeks back (here). As promised, now I am posting my mom’s NodeXL clustering results, focusing on just a few of the most intriguing (puzzling?) aspects. (You can read a step-by-step how-to on using NodeXL to cluster your Ancestry matches here, at Shelley Crawford’s blog.)
Mom’s matches for this clustering exercise were limited to those with 15 cM or greater shared; it simply gets too cluttered if I include everybody down to 6 cM.
Also in the photo below I have turned off the display for all clusters with less than 4 people. (NodeXL’s algorithms will cluster in groups of two, while other algorithms like Jonathan Brecher’s Shared Clustering tool use three as a minimum.)

Let’s look first at “Group 13”, the cluster at the bottom in navy blue that looks like 2 separate clusters to me. (I don’t fully understand how the algorithm works.) Below is group 13, zoomed in and with inter-group links turned off so you can look at the cluster itself more closely. Clearly, only one match links to both halves of this group. So, they’re not related as closely as one might think.
The additional photos below bear out that theory. On the left, “Cousin X” is highlighted; you can see that “X” shares a match with only 2 people (in addition to my mom). On the right, “Cousin B” is highlighted. “Cousin B” only matches others in the one subcluster, and nobody in the other subcluster.


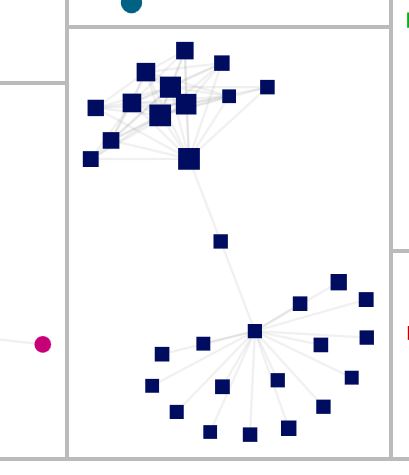
Another group that looks intriguing is one to my mom’s cousin “Sally Sue” (alias) who is fairly closely related to Mom. (You can tell she is more closely related to my mom by the size of the blue square. These matches look like a hub and spokes. “Sally Sue” is in the middle with the largest square; the others are more distantly related to my mother. (As an aside, the option to size the squares or dots by the shared cM amount is available in the NodeXL tool, but is not automatic.)
“Sally Sue’s” group, shown below with the outside links removed, is one in which she matches every single person in her cluster, but each of them only matches her (or, not shown, at least one person in a different cluster.)

The last cluster that is intriguing is shown below. This cousin, let’s call her Jane, appears to be in the “wrong” cluster. While she does have matches in her own cluster, she has many more matches in a different cluster.

One reason this might happen is that Jane and Mom could share DNA on, say, chromosome 1 (possibly with others in her group); the cousins in the other cluster could share DNA with mom on, say, chromosome 9, and then share DNA with Jane on chromosome 4. We don’t know for sure, since we don’t have segment info.
However, since clustering my mother’s matches in NodeXL and starting the draft of this post, I used Jonathan Brecher’s Shared Clustering tool, which groups “Jane” with the cluster where she has most of her matches.
On the face of it, that makes more sense. However, seeing “Jane” in a separate group (as below) could be useful for realizing that she may be connected on a different ancestral to my mother than the bulk of her matches. This suggests I need to be careful in analyzing Jane’s tree and ancestral surnames, vis-a-vis the matches in the other cluster.
In fact, I am finding that it is useful to cluster your shared DNA matches with more than one tool, as each uses different algorithms. (More on other clustering methods in a later post.)
