The other day, in the Facebook user group for the Shared Clustering Tool created by Jonathan Brecher, I saw a post about how different folks use the tool. I mentioned capturing MRCA information and aligning it to the clusters, but thought I would expound here in a blog post.
Before I begin, I’m making one basic assumption for this post — that you’ve already started playing with the Shared Clustering tool yourself.
First of all, I only use it for Ancestry matches at this time, primarily because that’s where I have the most matches (ditto for my mom and my dad) and because Ancestry currently doesn’t provide segment information.
Secondly, although the tool offers the option of downloading match data directly from Ancestry, I do not use that feature. Instead, I use the match and ICW (“In Common With”) files downloaded from Ancestry via DNAGedcom.com, which is, frankly, my go-to tool.
DNAGedCom’s CSV files are my go-to files because I’m most comfortable using Excel – one of the reasons I like Shared Clustering, actually – and because that’s how I started, and I’ve kept on. (Long story short, had I begun by using Ancestry’s Notes feature more effectively than I did, I could save myself some time, but I do it all in my DNAGedCom match file, and then update each subsequent download using VLOOKUP.)
An example of tracking on my mom’s Ancestry DNA match list (via DNAGedCom) is shown below:
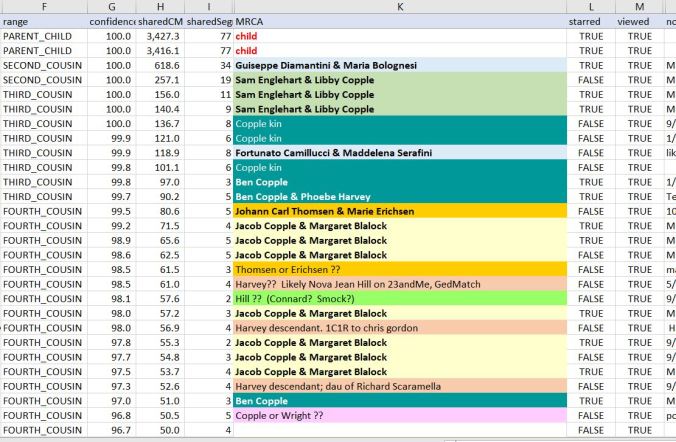
Color-coded by known MRCA. If I’m not certain of the MRCA, based on the clustering, I add comments like “Copple kin” or “Hill?”
I upload the MRCA information to the completed Shared Clustering file via VLOOKUP since Jonathan has so nicely included the Test ID in the tool. Usually, I will take the time to color-code the MRCA data in the Shared Clustering result file, simply so I can zoom out and easily see which cluster “belongs” to which possible MRCA.
Below you can see where I’ve zoomed out to see a fairly large clustering of my matches. I’ve zoomed out to 10% and have highlighted 284 matches. Per Jonathan Brecher’s Wiki, the red color indicates likely shared DNA. The gray color indicates that, although the two matches (one in the row and one in the column) do not share DNA with each other, they likely share with a third person. You can also see (barely) my color-coded MRCA notes on the left side of the image.
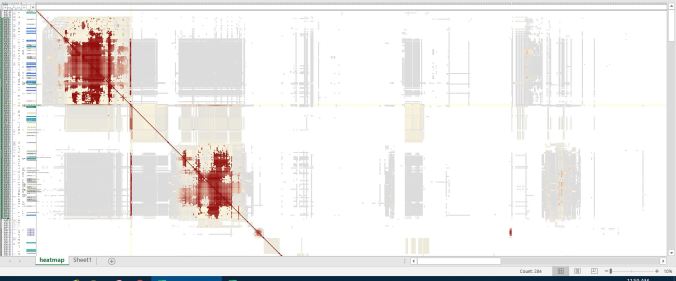
So, let’s zoom in a bit on this large cluster.
Below, notice that I have highlighted in green (as indicated by the yellow arrows) one of my closest matches (although she is a 4th cousin 1 removed). She and I share a common ancestral couple: Jacob Copple and Margaret Blalock, my 4th great-grandparents. We also share 3 segments of DNA, and two of those segments are indicated here, in the cluster of red at the top left, and the cluster of red (circled in yellow). Note the vertical line of red that merges into a vertical line of green — the red is showing me that she and I share DNA with the bulk of the two circled groups.
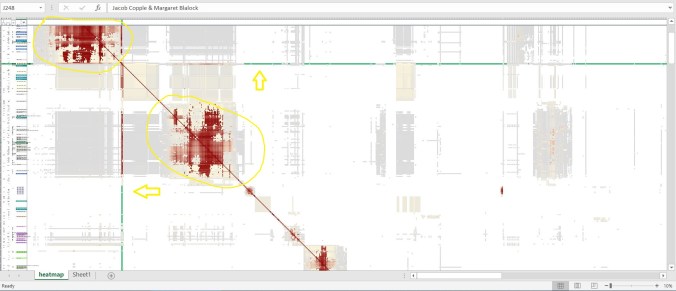
What does this tell us? First it indicates two different segments of DNA, so if we go far enough back in time, it would be 2 different ancestors. Second, she and I likely share those 2 segments of DNA. Third, all the associated gray indicates a link between these 2 segments of DNA, so these matches are all most likely related to me via one ancestor and upstream of that ancestor.
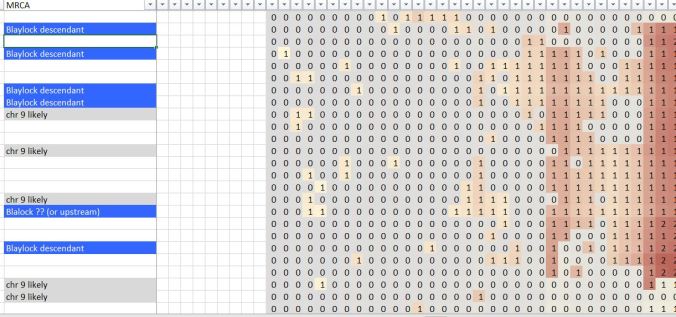
Let’s zoom in even further and look more closely, now at my MRCA/clustering information I’ve imported from DNAGedCom. The blue labels refer to matches who are Blalock/Blaylock descendants. The gray labels reference a known match on Chromosome 9.

This would seem to point at the connection being on a segment of chromosome 9 and also relating to Margaret (Blalock) Copple. This does not mean these matches share Margaret (Blalock) Copple as an ancestor with me, but rather one of Margaret’s own ancestors.
To put it another way, I have a clue! These shared cluster results would seem to indicate that I need to do more research on Margaret (Blalock) Copple’s line, and connect with the matches who are Blalock descendants. And, at other DNA vendors, I should connect with matches who share the same segment on chromosome 9 to find out how or if they might be connected to a Blalock/Blaylock ancestor.
Let’s look at the second cluster, below. This zoomed-in, partial view show matches who potentially share a segment on chromosome 13 with me. Based on their Ancestry tree information, there are some who share Jacob Copple and Margaret Blalock as common ancestors with me (just one shown here).
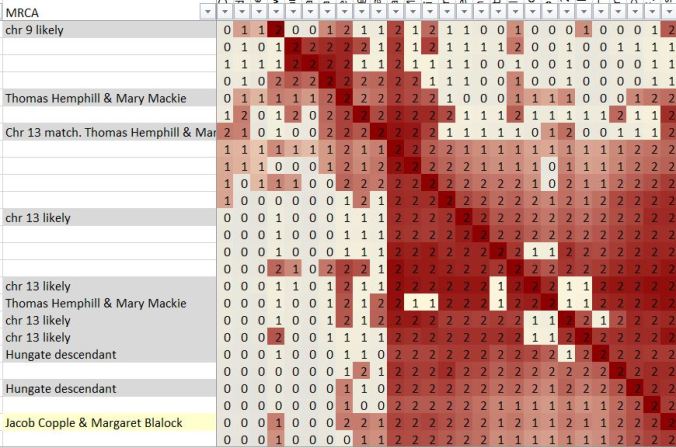
Other matches in this cluster have no Copple or Blalock at all in their tree. Their trees could be incomplete or incorrect, of course (as could mine!) OR, their trees could be indicating a shared ancestor further “upstream” (meaning, a possible ancestor of Margaret (Blalock) Copple. To that end, I’ve noted where there are Hemphill and Hungate ancestors in my matches’ trees.
These Hemphill and Hungate families, according to the Ancestry trees of my matches, hailed from Kentucky (where Margaret Blalock was born ca. 1810) and a branch of the Hungate family ended up in Washington County, Indiana in the 1810’s – 1830’s. This is the same county Margaret lived in during the same time frame. Although not definitive, it’s worth noting as a potential clue.
In summary, because the two groups are related (as indicated by all the gray associated with them), both DNA segments the groupings indicate are more likely to have been inherited by me from Margaret (Blalock) Copple (and, ultimately, her ancestors) rather than from her husband Jacob Copple.
Here’s another example of a cluster on my Copple line, where you can quickly see, from the teal color on the left-hand side, that these matches share an MRCA. In fact, I use the teal to indicate more than one generation of Copple ancestors (all also ancestors of Jacob Copple who married Margaret Blalock).
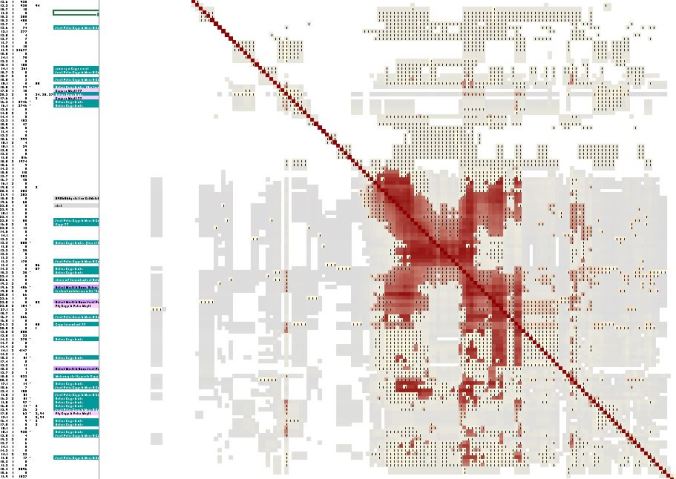
The last example is a line from my dad’s side. As with the Copple and Blalock lines from my mother’s side, this paternal line is rooted in the United States from at least 1800 if not decades before that.
The bulk of these DNA matches share my third great-grandparents, Anderson Lamburth and Ermine Farley (or Farnham). However, they are clearly grouped in two clusters, so that one set may share Lamburth DNA and another set Farley DNA, or “upstream” (as in Anderson’s mother and Anderson’s father, or Ermine’s two parents).
Most intriguing is the linking between the two clusters. Not just the general gray, but the vertical red lines indicated by the blue arrow. I need to look more closely at these two matches — their names will be in the column headers (not shown here for privacy reasons).
One, they likely share 2 DNA segments with me. Two, they clearly share DNA with the small cluster on the upper left, as well as the larger cluster on the lower right. AND the folks in the middle who are only indirectly related (indicated by gray) to the two obvious clusters.
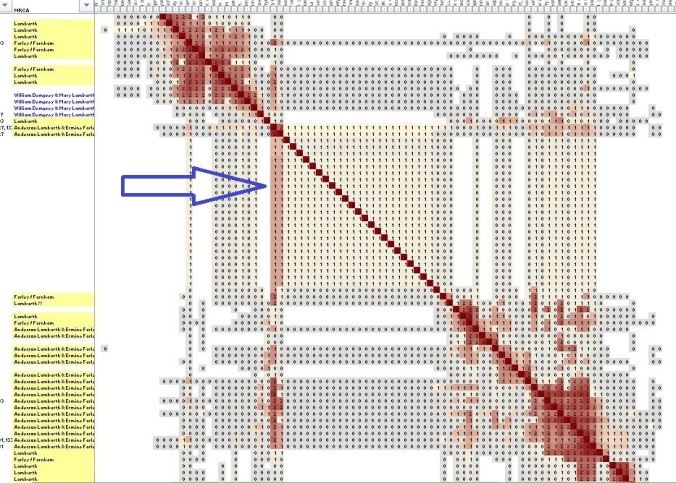
One other item to note in this cluster. Some of the MRCAs are not highlighted in yellow. That’s legit; referenced is the granddaughter of Anderson & Ermine, Mary (Lamburth) Dempsey, who was my great-grandma and her husband William. Clearly, the segment shared here relates to Mary rather than William.
If you use the Shared Clustering tool to visualize your Ancestry DNA matches, do you use any visualization aids to assign clusters to ancestors? Perhaps you make better use of the Notes field than I do?
Cite/link to this post: Cathy M. Dempsey, “How I use the Shared Clustering Tool,” Genes and Roots, posted 21 Oct 2019 (https://genesandroots.com : accessed (date)).

Good job, Cathy. It was interesting to read how you are using Jonathan’s tool. I do the download directly from Ancestry for the Shared Clustering tool. I recently took the DNA test so the first run was without any notes. As I work through my matches things will come together as I’m including the cousin level (child of the MRCA) MRCA at the beginning of notes. For example, 3C1R (Virginia) William A. W. DEMPSEY and Sarah Ann WOOD. I concur with Jonathan that the cluster represents an ancestor of only one of the MRCA. Including the full names and the name of the child is a bit too much information for cluster work. However, the notes are also used in Genome Mate Pro and help with searching and sorting notes.
LikeLike
I agree, Cathy re: the cluster representing only one ancestor. It was, in fact, as I was putting together this blog post and studying the visuals that I realized – duh! the 2 clusters I mention above are two segments that my mom (and the group) inherited from Margaret (Blalock) Copple rather than her husband. None of the matches I can validate at other vendors as matching on those segments match any of Jacob Copple’s ancestors. I love Shared Clustering for the detail visuals it provides!
LikeLiked by 1 person